Des réseaux, des textes et de la Statistique !
Depuis les travaux précurseurs de Moreno (1934), l’analyse des réseaux est devenue une discipline forte, qui ne se limite plus à la sociologie et qui est à présent appliquée à des domaines très variés tels que la biologie, la géographie ou l’histoire. L’intérêt croissant pour l’analyse des réseaux s’explique d’une part par la forte présence de ce type de données dans le monde numérique d’aujourd’hui et, d’autre part, par les progrès récents dans la modélisation et le traitement de ces données.
En effet, informaticiens et statisticiens ont porté leurs efforts depuis plus d’une dizaine d’années sur ces données de type réseau et ont proposé de nombreuses techniques permettant leur analyse. Les méthodes de clustering permettent en particulier de découvrir une structure en groupes cachés dans le réseau. Rappelons que le clustering est une technique qui vise à regrouper les individus (possiblement en grand nombre) en un nombre limité de groupes homogènes afin de faciliter l’interprétation des données. Dans ce cadre, les méthodes statistiques présentent l’avantage d’offrir une segmentation fine des données dont l’interprétation est facilitée par le modèle statistique sous-jacent.
Malgré les nombreux développements dans ce domaine, l’analyse conjointe des réseaux et des textes associés n’a reçu qu’une attention très limitée, alors même que la plupart des réseaux sociaux sont aujourd’hui associés à du texte (emails, Facebook, Twitter, …). Dans un travail récent, nous avons proposé une nouvelle méthodologie statistique, baptisée STBM (Stochastic Topic Block Model), qui permet de segmenter les nœuds (individus) d’un réseau avec arêtes textuelles, tout en identifiant les thèmes de discussions utilisés. STBM requiert uniquement la donnée d’un ensemble d’échanges de textes entre des individus, ou plus généralement entre des entités. Par exemple, on peut considérer les échanges de textes entre des individus d’un réseau social, ou les échanges d’emails entre les employés d’une entreprise, ou encore les co-publications de brevets ou publications scientifiques. Il est intéressant de noter que, d’un point de vue mathématique, le modèle STBM généralise deux modèles statistiques très populaires : le Stochastic Block Model (SBM), dédié au clustering de nœuds d’un réseau, et le Latent Dirichlet Allocation (LDA), dédié à l’analyse de textes.
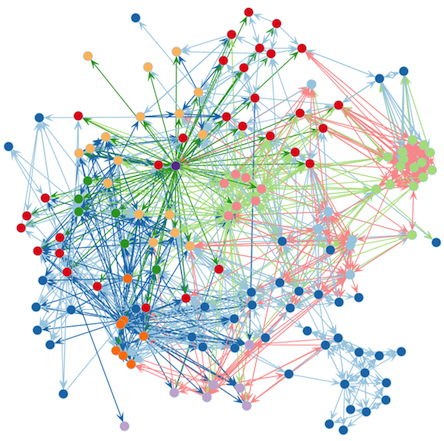
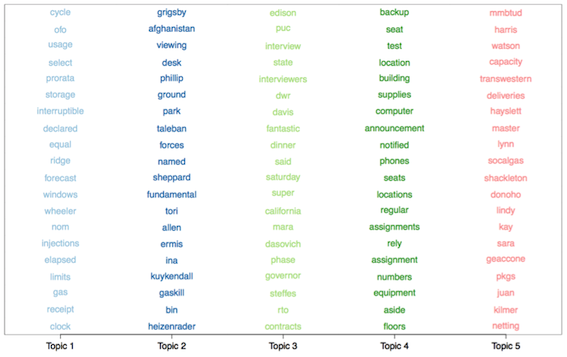
A titre d’exemple, STBM a été appliqué à l’analyse des emails de l’entreprise Enron qui a connu au début des années 2000 une banqueroute très médiatisée. STBM a identifié que le réseau contenait 10 groupes d’invidus et 5 thèmes de discussion. La figure ci-dessous permet de visualiser à la fois la classification des individus (couleurs des nœuds) et les thèmes majoritaires de discussions (couleurs des arêtes). Le tableau du dessous permet d’interpréter les thèmes de discussion identifiés par la méthode en observant les mots les plus fréquents de chaque thème. Il est intéressant de noter que STBM fait apparaître, parmi des thèmes attendus et liés aux activités d’une entreprise de Gaz, deux thèmes particuliers (topics 2 et 3) et qui sont en fait deux des principaux pans du scandale Enron : les relations troubles entretenues par Enron et la Maison Blanche avec les Talibans en Afganistan ainsi que la mise en cause d’Enron dans la banqueroute de la compagnie Edison.
Il est possible d’explorer les données Enron au travers de la méthode STBM avec l’application en ligne disponible à l’adresse suivante : up5.fr/enron.
Références :
C. Bouveyron, P. Latouche and R. Zreik, The Stochastic Topic Block Model for the Clustering of Networks with Textual Edges, Statistics and Computing, in press, 2017.
Contacts
Charles Bouveyron est professeur à l'université Côte d'Azur. Il est membre du laboratoire Jean-Alexandre Dieudonné (LJAD - CNRS & Université Nice Sophia Antipolis).
Pierre Latouche est professeur à l'université Paris-Descartes. Il est membre du laboratoire Mathématiques appliquées à Paris 5 (MAP5 - CNRS & Université Paris-Descartes).